


Ученые НИУ ВШЭ научили нейросеть учиться на несколько порядков эффективнее

Нейросетевые генеративные модели в последние годы достигли впечатляющих результатов, однако важной задачей остается повышение эффективности их работы. Исследователям факультета компьютерных наук НИУ ВШЭ и AIRI удалось оптимизировать обучение нейросети StyleGAN2, создающей реалистичные картинки, сократив число обучаемых параметров на четыре порядка. При этом качество полученных изображений осталось высоким. Результаты работы представлены в докладе на конференции NeurIPS 2022.
Современные модели умеют генерировать человеческие лица в таком качестве, что их не отличить от лиц настоящих людей, и в то же время эти лица — новые, то есть таких людей в мире никогда не существовало. Одним из многообещающих типов генеративных моделей стала GAN (Generative Adversarial Network) — генеративно-состязательная сеть. Это комбинация из двух нейронных сетей, одна из которых (генератор) производит образцы, а другая (дискриминатор) — старается отличить правильные образцы от неправильных. Так как генератор и дискриминатор имеют противоположные цели, между ними возникает антагонистическая игра, которая способствует быстрому достижению общей цели — созданию реалистичного изображения.
Основная проблема при обучении генеративных моделей — сбор большого количества изображений высокого качества. Для того чтобы научиться генерировать реалистичные лица в высоком разрешении, сети понадобится порядка 100 тысяч разнообразных лиц. К сожалению, собрать такой датасет сложно, особенно в некоторых ситуациях, когда, например, нужно получить портреты в стиле конкретного художника или персонажей из вселенной Pixar.
Однако даже в экстремальных случаях, когда доступно несколько примеров стилизованных изображений или только текстовые описания, есть методы для дообучения генеративной модели, которая изначально училась на большом датасете обычных изображений. «Ранее для адаптации генератора под новый домен (например, портреты в стиле Pixar) дообучали почти все параметры — это порядка 30 млн. Нашей целью было уменьшить их число, так как мы понимали, что не имеет смысла учить заново весь генератор, чтобы изменить только стиль созданного ранее изображения», — отметил Дмитрий Ветров, заведующий Центром глубинного обучения и байесовских методов НИУ ВШЭ.
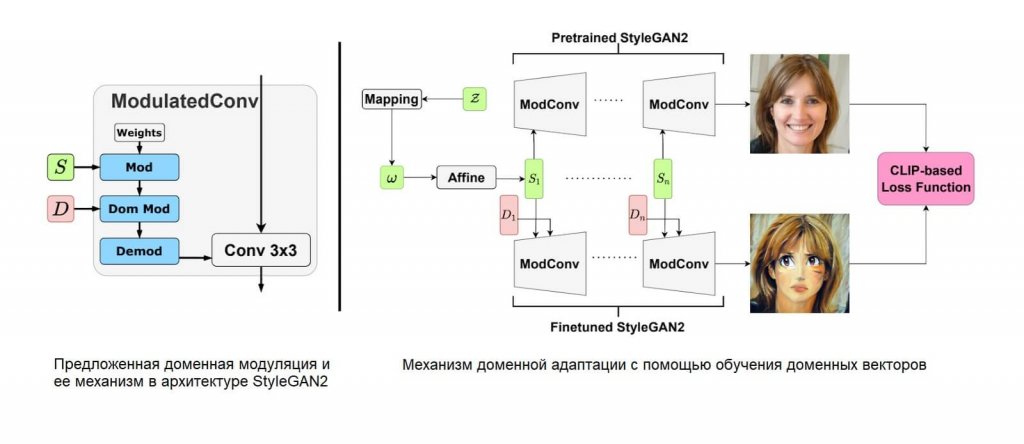
В статье “HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks” ученые Центра глубинного обучения и байесовских методов НИУ ВШЭ описали новый подход к дообучению генеративной модели StyleGAN2. Это генеративная нейросеть, которая преобразует случайный шум в реалистичную картинку. Исследователям удалось оптимизировать ее обучение, сократив число обучаемых параметров (весов) на четыре порядка за счет обучения дополнительного доменного вектора.
В архитектуре сети StyleGAN2 есть специальные трансформации (модуляции), с помощью которых входной случайный вектор контролирует семантические признаки выходного изображения, такие как пол, возраст и т.д. Ученые предложили обучать дополнительный вектор, который определяет домен выходных изображений через аналогичные модуляции.
Предложенная доменная модуляция и ее механизм в архитектуре StyleGAN2. (Справа) Механизм доменной адаптации с помощью обучения доменных векторов.
«Если дополнительно обучать только такой доменный вектор, то домен генерируемых картинок меняется так же хорошо, как если бы мы дообучали все параметры нейронной сети. Это кардинально снижает число оптимизируемых параметров, так как размерность такого доменного вектора всего 6000, что на порядки меньше, чем 30 млн весов нашего генератора», — рассказал Айбек Аланов, первый автор статьи, стажер-исследователь Центра глубинного обучения и байесовских методов НИУ ВШЭ.
Сравнение предложенного подхода с основным бейзлайном (StyleGAN-NADA). Методы показывают сопоставимое визуальное качество, притом что предложенный подход имеет на порядки меньше обучаемых параметров.
На основании полученных результатов ученые предложили первый метод мультидоменной адаптации, который позволяет адаптировать модель на несколько доменов сразу. Такая значительная оптимизация дообучения на новые домены сокращает время обучения и используемую память. С помощью такого метода можно обучить гиперсеть, которая имеет меньше параметров, чем исходный генератор, но хранит в себе сотни и даже тысячи новых доменов.

Фото: Pexels; НИУ ВШЭ
мероприятий
В США разработали мессенджер, который работает без интернета и сотовой связи